
EDAPS: Enhanced Domain-Adaptive Panoptic Segmentation
Suman Saha , Lukas Hoyer, Anton Obukhov, Dengxin Dai, and Luc Van Gool
arxiv.org 2023

Suman Saha , Lukas Hoyer, Anton Obukhov, Dengxin Dai, and Luc Van Gool
arxiv.org 2023
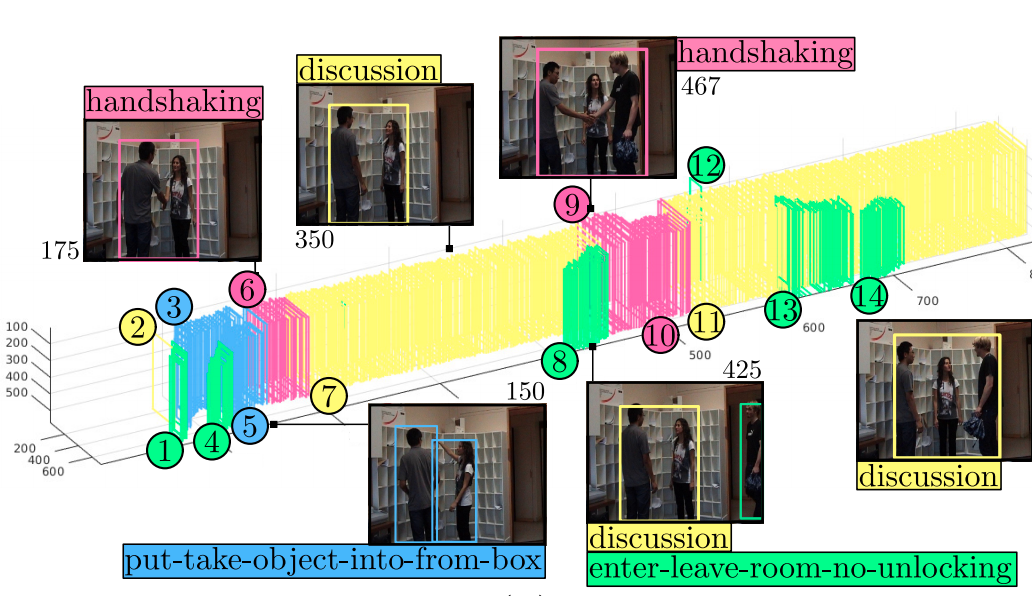
Yifan Lu, Gurkirt Singh, Suman Saha , Luc Van Gool
WACV 2023

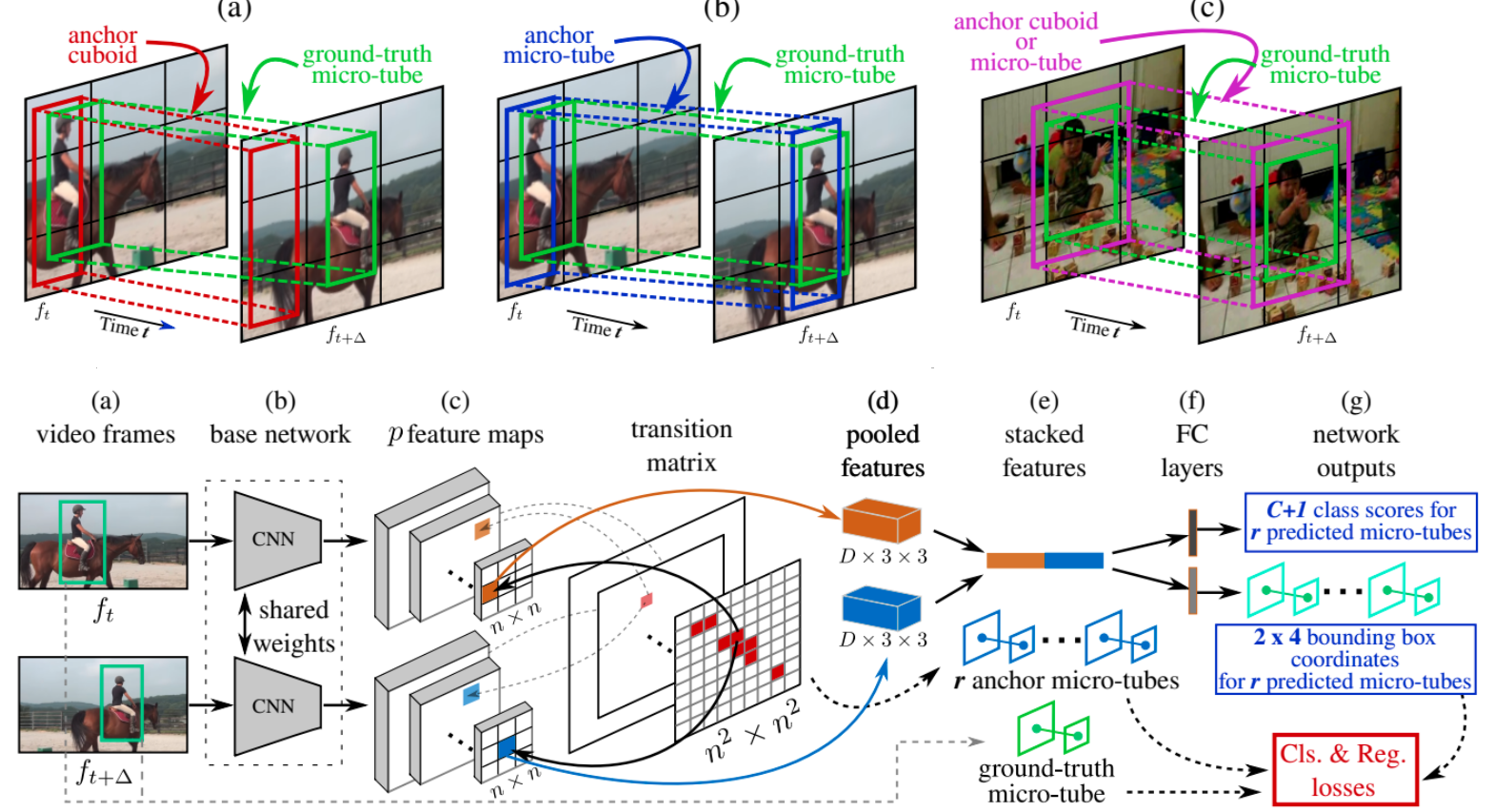
Gurkirt Singh, Vasileios Choutas, Suman Saha , Fisher Yu, Luc Van Gool
WACV 2023
Suman Saha , Anton Obukhov, Danda Pani Paudel, Menelaos Kanakis, Yuhua Chen, Stamatios Georgoulis, Luc Van Gool
CVPR 2021
Lukas Hoyer, Dengxin Dai, Yuhua Chen, Adrian Köring, Suman Saha , Luc Van Gool
CVPR 2021

Ankush Panwar, Pratyush Singh, Suman Saha , Danda Pani Paudel, Luc Van Gool
FG 2021
Gurkirt Singh, Suman Saha, Fabio Cuzzolin et al.
IEEE TPAMI 2021
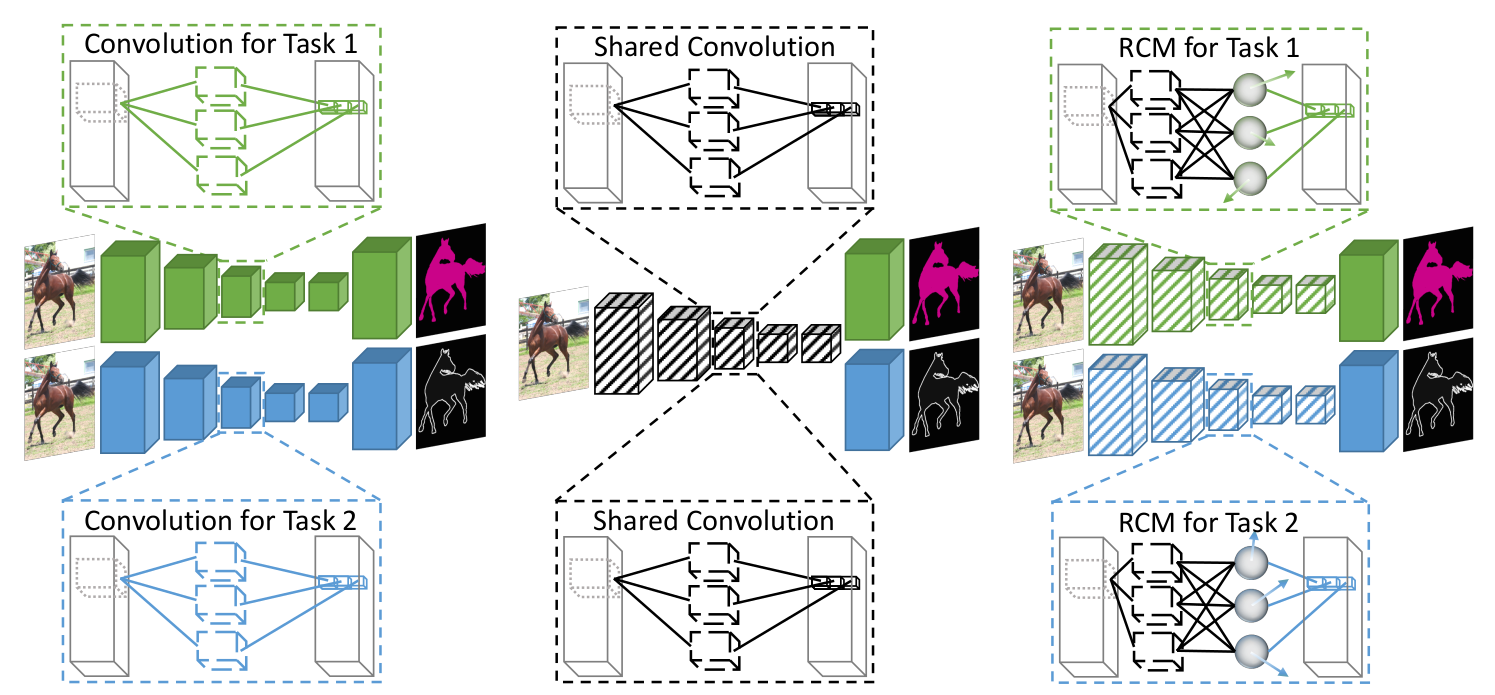
Menelaos Kanakis, David Bruggemann, Suman Saha, Stamatios Georgoulis, Anton Obukhov, Luc Van Gool
ECCV 2020

Suman Saha , Wenhao Xu, Menelaos Kanakis, Stamatios Georgoulis, Yuhua Chen, Danda Pani Paudel, Luc Van Gool
CVPR WORKSHOP 2020

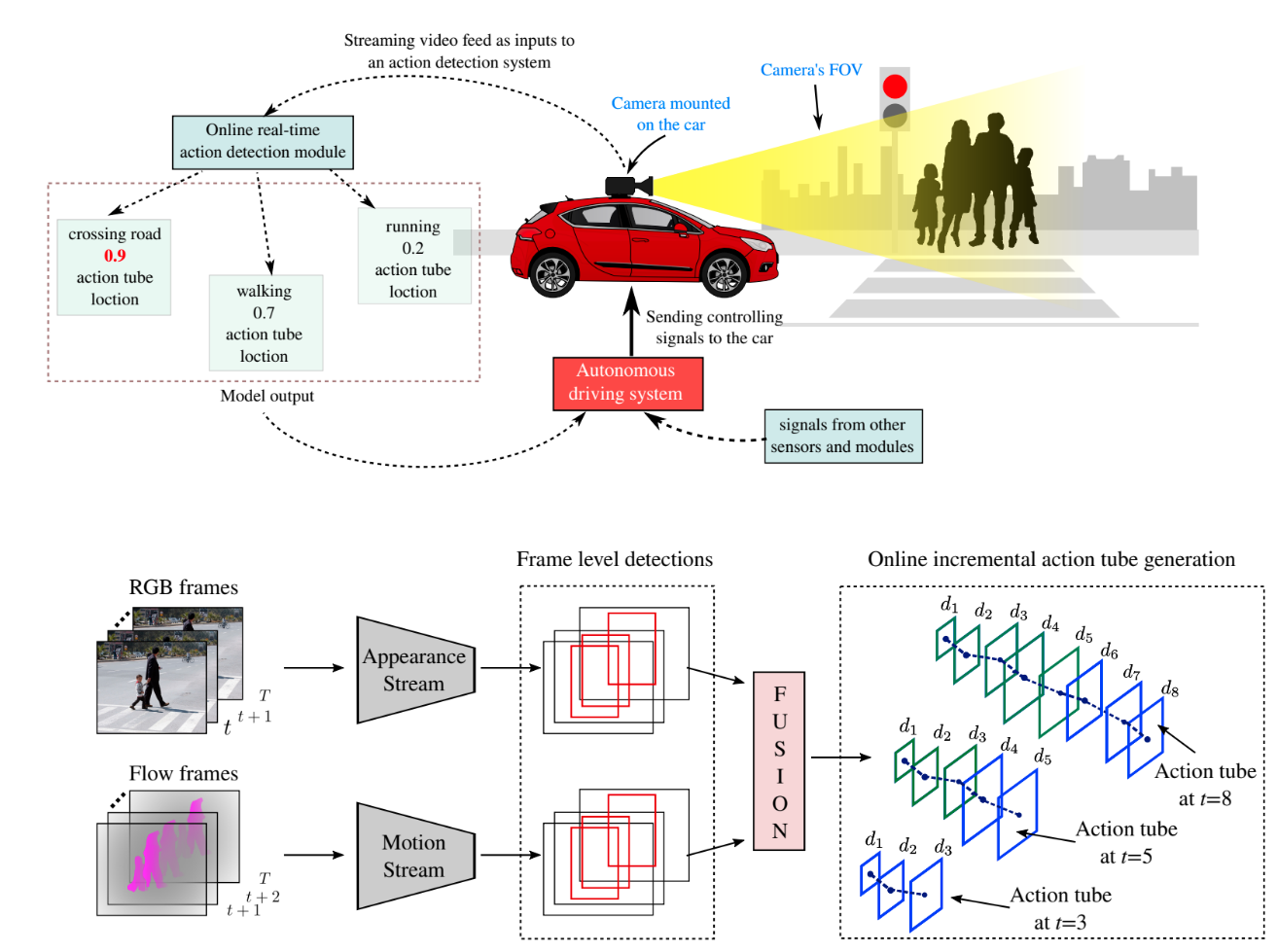
Suman Saha , Gurkirt Singh, Michael Sapienza, Philip H. S. Torr, Fabio Cuzzolin
Book title: Modelling Human Motion: From Human Perception to Robot Design
Publisher: Springer International Publishing, pages: 141-161, ISBN: 978-3-030-46732-6, year: 2020.
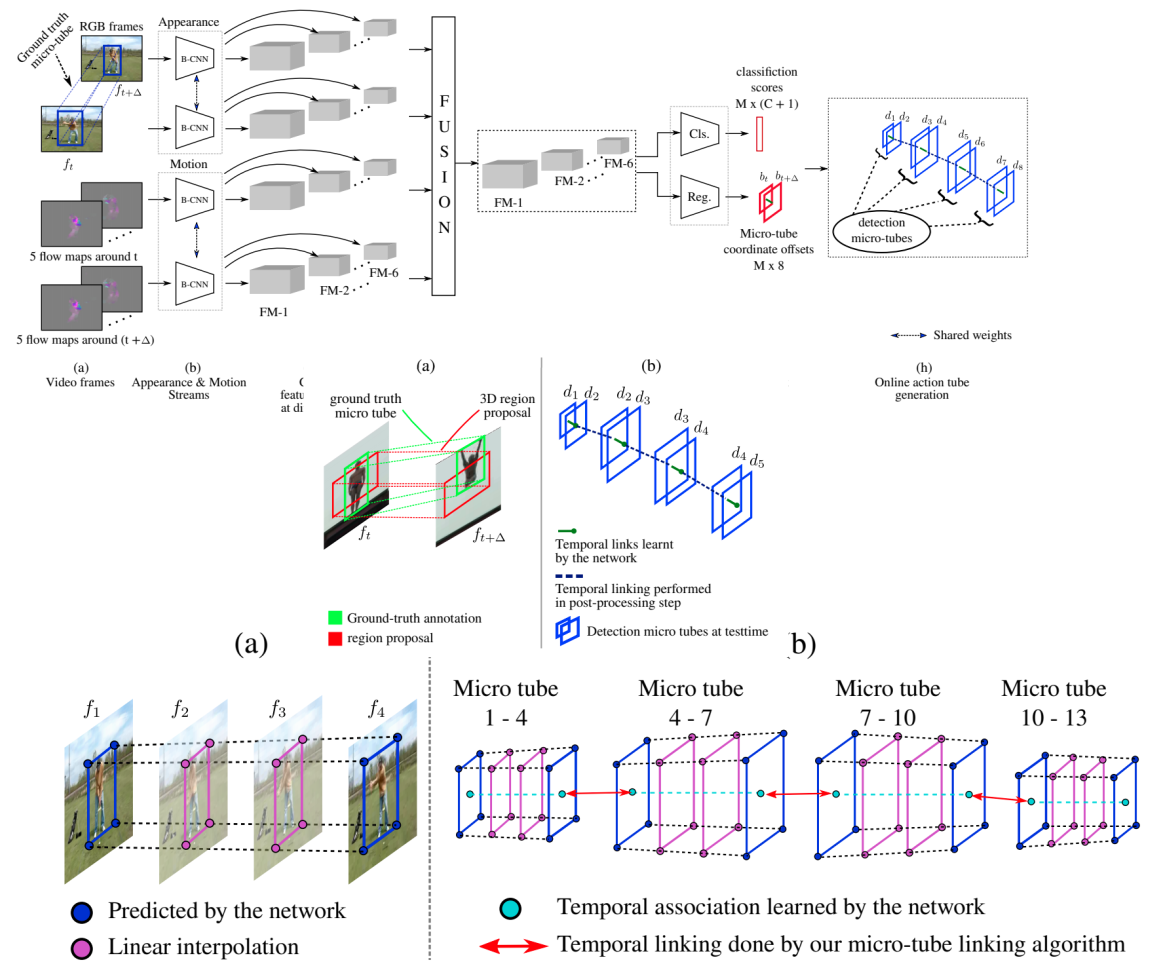
Suman Saha , Gurkirt Singh, Fabio Cuzzolin
arXiv 2020.
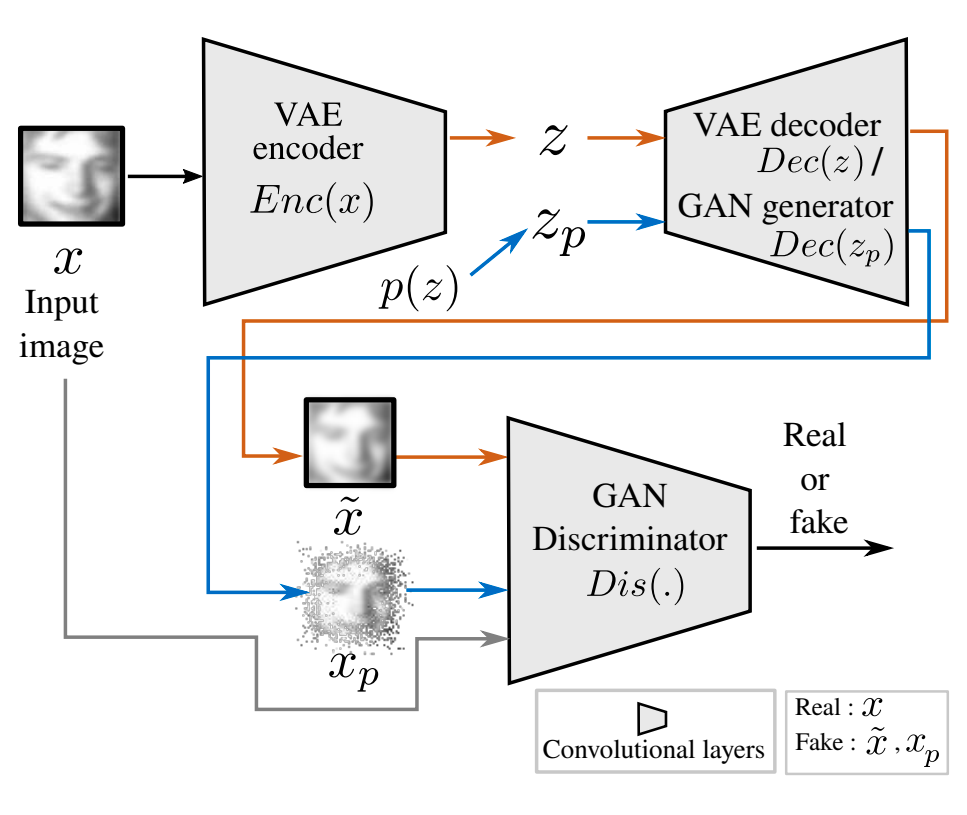
Suman Saha, Rajitha Navarathna, Leonhard Helminger, Romann M. Weber
CVPR 2018 Workshops
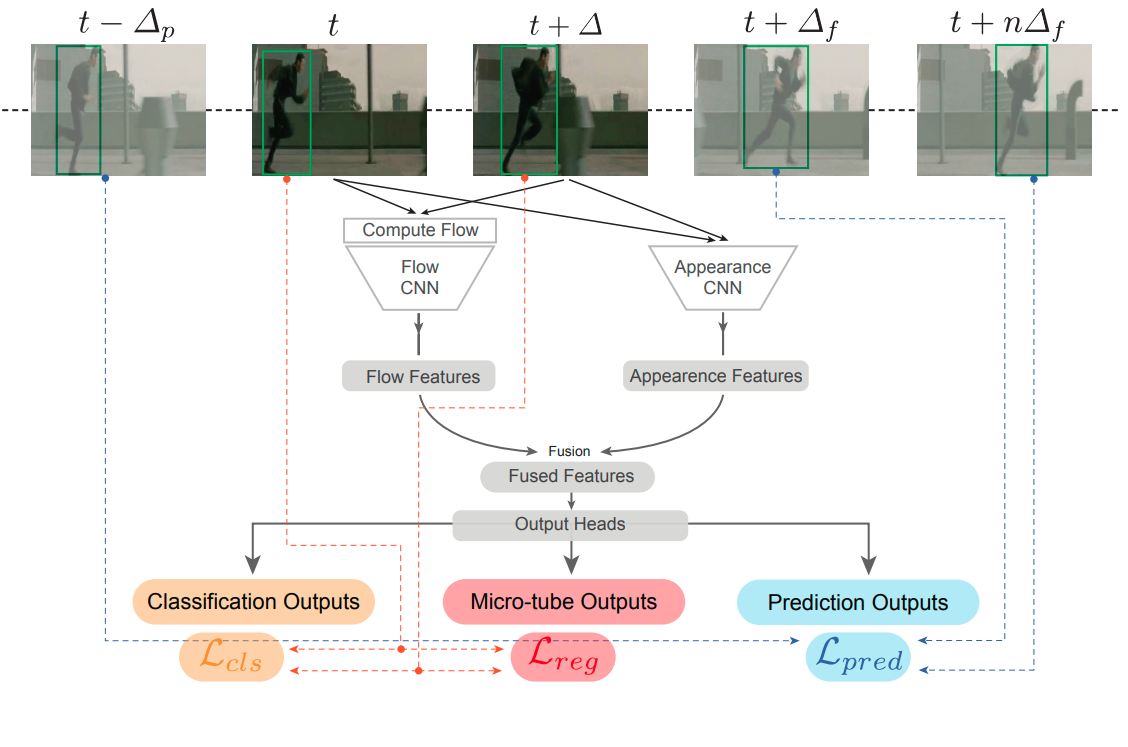
Gurkirt Singh, Suman Saha, Fabio Cuzzolin
ECCV 2018 Workshops
Harkirat Singh Behl, Michael Sapienza, Gurkirt Singh, Suman Saha, Fabio Cuzzolin, Philip H. S. Torr
BMVC 2018 (Oral)
Suman Saha
PhD thesis, Oxford Brookes University, United Kingdom, 2018
Gurkirt Singh, Suman Saha, Fabio Cuzzolin
ACCV 2018
Valentina Fontana, Manuele Di Maio, Stephen Akrigg, Gurkirt Singh, Suman Saha, Fabio Cuzzolin
arXiv 2018
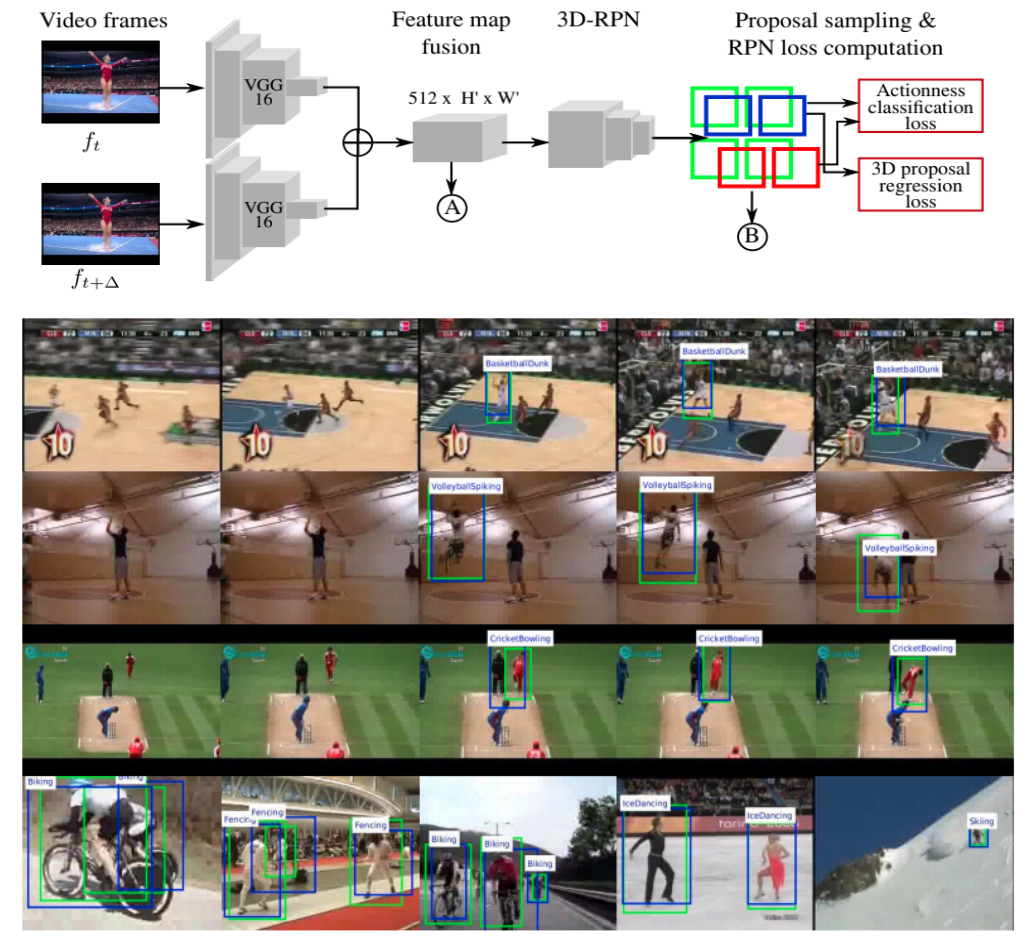
Suman Saha, Gurkirt Singh, Fabio Cuzzolin
ICCV 2017
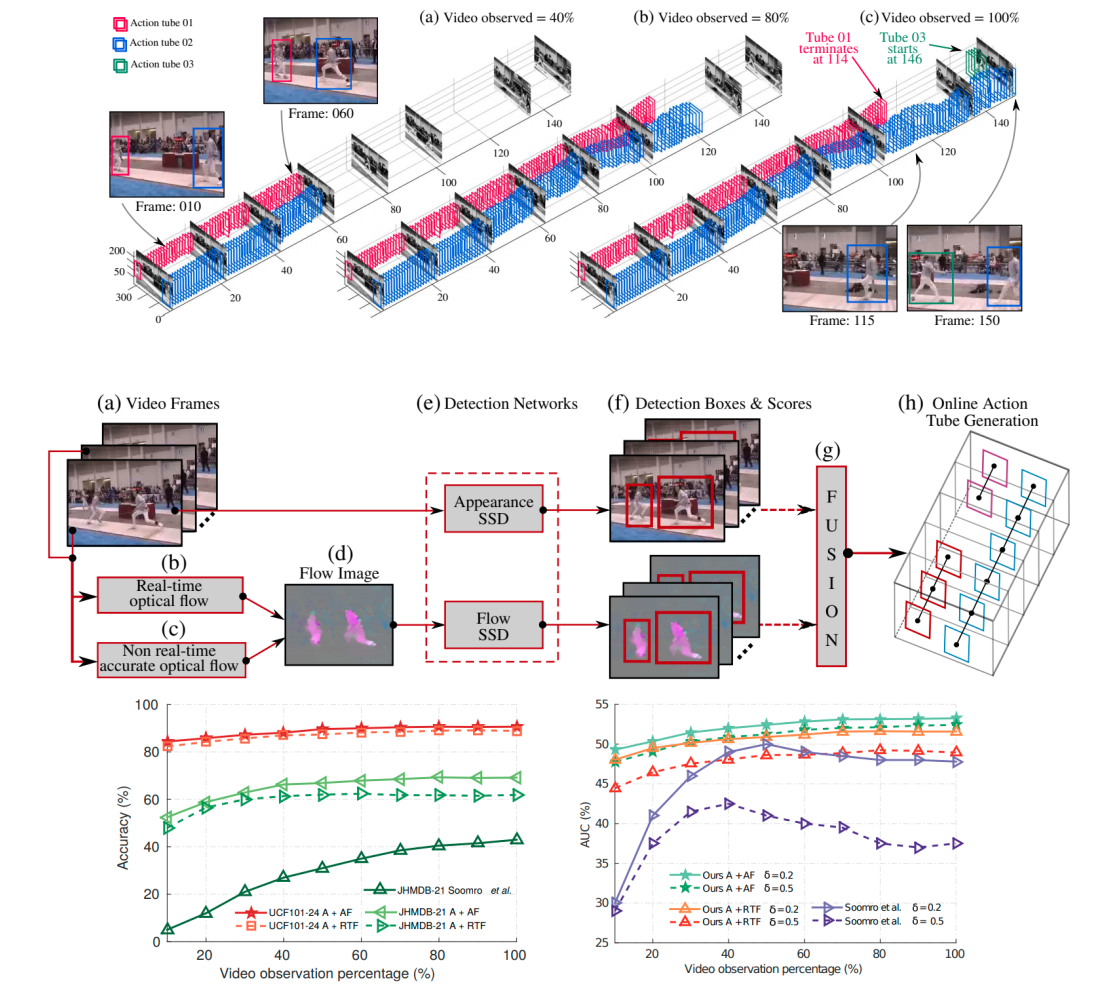
Gurkirt Singh, Suman Saha, Michael Sapienza, Philip H. S. Torr, Fabio Cuzzolin
ICCV 2017

Suman Saha, Gurkirt Singh, Michael Sapienza, Philip H. S. Torr, Fabio Cuzzolin
arXiv, 2017
Fabio Cuzzolin, Michael Sapienza, Patrick Esser, Suman Saha, Miss Marloes Franssen, Johnny Collett, Helen Dawes
Gait & Posture, Volume 54, May 2017, Pages 127-132
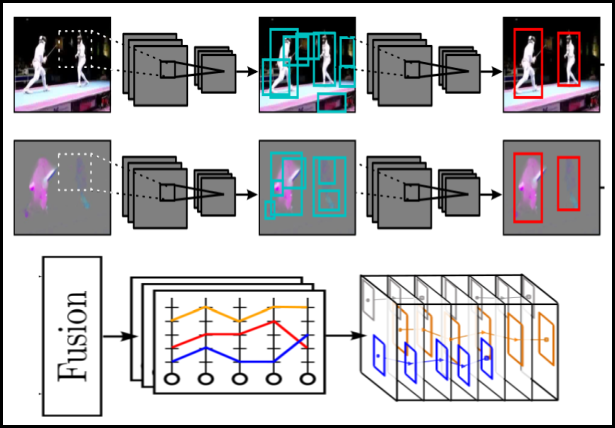
Suman Saha, Gurkirt Singh, Michael Sapienza, Philip H. S. Torr, Fabio Cuzzolin
BMVC 2016

Suman Saha, Ashutosh Natraj, Sonia Waharte
Aerospace Electronics and Remote Sensing Technology (ICARES), 2014 IEEE International Conference on
Suman Saha
European Journal of Applied Sciences and Technology [EUJAST] Volume 1 (1), March 2014

Suman Saha
MSc Thesis , University of Bedfordshire, Uited Kingdom. January 2014
Before joining ETH Zürich,
I was a Research Associate (RA) or a postdoctoral researcher at the
Department of Computing and Communication Technologies,
Oxford Brookes University, where I spent four wonderful years (included my PhD studies).
I have received my PhD degree under the supervision of
Professor Fabio Cuzzolin
at Oxford Brookes University, United Kingdom.
Professor Nigel Crook
and
Dr Tjeerd Olde Scheper
where my PhD co-supervisors.
My PhD thesis topic was
Spatio-temporal Human Action Detection and Instance Segmentation in Videos.
The two main objectives of my PhD thesis were to propose:
(1) efficient algorithms to locate (in space and time) multiple co-occurring human action instances present in realistic videos;
(2) powerful video level deep feature representation to improve the state-of-the-art action detection accuracy.
Besides, I was an active member of the
Artificial Intelligence and Vision Research Group led by Professor Fabio Cuzzolin.
I consider myself fortunate to have an opportunity to work closely with the world renowned
Torr Vision Group (TVG)
in the Department of Engineering Science at University of Oxford. More specifically, during my PhD, I worked with my PhD guide
Dr Michael Sapienza
and Professor Philip H. S. Torr. who is the
founder of TVG.
During summer 2017, I received a wonderful opportunity to work with
Dr Romann Weber
Senior Research Scientist and Head of Machine Intelligence and Data Science Group at Disney Research Zurich (DRZ).
At DRZ, I wokred for the project named
unsupervised and semi-supervised learning of audience facial expressions using deep generative models.
We improved the classification accuracy by 9% over the existing method.
I have completed my Master's study from the
Department of Computer Science and Technology,
University of Bedfordshire (UoB), United Kingdom.
During my MSc thesis work (i.e., in 2013-2014), I proposed a novel
realtime algorithm
for frontal obstacle detection and avoidance for low cost unmanned aerial vehicles
(UAVs).
The related publication can be accessed using this link.
My MSc thesis supervisors were
Dr Ashutosh Natraj
and
Sonia Waharte
, post doctoral researchers in the Department of Computer Science, University of Oxford.
Before pursuing my Master's study in UK, I worked as a Software Analyst at the
the Research and Development and Scientific Services division,
Tata Steel Ltd. India.
At R&D Tata Steel, I worked under the supervision of
DR. Sumitesh Das,
Chief (Global Research Programmes) at Tata Steel Ltd.
My CV can be viewed by clicking this
link.
I received my Polytechnic Diploma Engineering degree in Computer Science
from
Siddaganga Polytechnic College,
India.